
This post on network operations is the fourth in my Back to Basics series. The first three posts covered Gathering Requirements, Network Design, and Network Implementation.
Once ACME Corporation’s data centre network has been implemented, it will need care and feeding, which consists of operations and optimizations. There are a few key ingredients to successful network operations.
Documentation #
ACME’s data centre project produced several documents that should be stored in two locations. First, all project documents should be stored in a read-only project archive. It will be used to answer questions like “why did you do it this way?” or “what were you thinking?”. This archive may prove helpful to future projects as they try to follow established standards. Second, a copy of all documents deemed applicable to network operations (i.e., cable plans, diagrams, configuration templates, IP addressing plans, naming and numbering conventions) should be turned over to the network operations team.
Some of ACME’s resources would rather launch from one of the company’s giant slingshots than update documentation, but it is critical to the success of the entire team to treat these documents as living. No network change should be considered fulfilled until all corresponding paperwork is complete.
Unless there is some security policy preventing it, sharing read-only versions of these documents with other operations and support teams goes a long way to helping them understand what they are using. Other teams are far more likely to blame the network for all their problems when they can only visualize a black box. Demystify the network whenever and wherever you can.
Network Visibility #
Network visibility comes in many forms; a few are critical to the network’s success and can shift network operations from reactive to proactive. The following sections describe forms of network visibility that should be pursued for ACME. General categories of network visibility tools are root cause analysis, capacity planning and security.
Syslog Collector: A syslog collector that can index, store, and query all syslog messages from all network devices should be implemented. To be most effective, this syslog collector should collect logs from servers, storage systems, databases, applications and security appliances in addition to network equipment. Querying such a collection of syslog messages would greatly help with correlating events when troubleshooting and performing root cause analysis.
Configuration Management: Every network device requires a configuration. For fast, easy recovery during equipment replacement and failure, all configurations should be stored and archived, with a history of changes. This type of tool is invaluable during an audit.
Network Performance Monitor (NPM): A network performance monitor is a category of tools that can help take the guesswork out of capacity planning. These tools can report on link utilization, latency, and round-trip times, and generate alerts when thresholds are crossed. Data from these tools can serve as inputs for sizing security appliances and for creating and maintaining accurate Quality of Service (QoS) policies. Network statistics may be gleaned from both real-world and synthetic traffic and are usually collected in the IP Flow Information Export (IPFIX) format.
Application Performance Monitor (APM): Application performance monitors take performance information a few steps deeper and can provide information about applications that an NPM tool cannot. An APM can collect information about transaction times and report on the overall user experience.
Health Monitor: A useful health monitor reports on information such as up/down status, Central Processing Unit (CPU) utilization, link/bandwidth utilization, memory utilization, power consumption and temperature, to name a few. This product should be evaluated to make sure it meets the needs of monitoring a highly available data centre network.
Packet Capture: Packet captures are one of the main tools used to perform a deep dive into network and application performance problems. There are many packet capture tools available; some are open source, and some are sold for a fee.
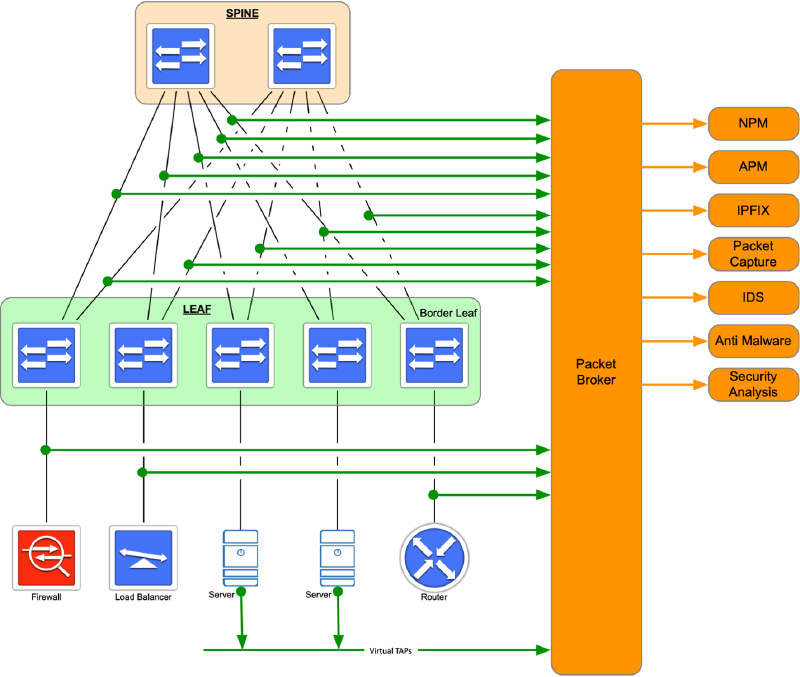
Network Visibility Fabric (NVF): Implementing an NVF into ACME’s data centre network would provide an excellent foundation for network visibility. Through a series of Test Access Points (TAPs) installed at all layers of the network, a copy of all packets can be sent out-of-band to a central aggregation point or packet broker, where it can be used by the tools mentioned above. Because an NVF sends copies of packets out-of-band, there is no performance impact to production traffic or the production network. Traffic is copied for monitoring, security, and analysis as the traffic continues to pass through the network unimpeded. Also, because there is a central collection point for all packets, it is simpler to broker packets to the tools that need them. An organization usually requires fewer tools of each type (i.e., monitoring, security, analysis) because initial packet collection is performed by the broker rather than by the specific tool, and no redesign is required to implement a new tool. The key is the central collection of packets.
An NVF can place tools inline with production traffic, allowing tools such as security devices (e.g., Intrusion Prevention System (IPS), anti-malware, Data Loss Prevention (DLP)) to be implemented without a network redesign.
Using virtual TAPs, an NVF can TAP into virtualized environments that have historically been challenging to troubleshoot.
IPFIX generation can be very resource-intensive on network devices, and sending IPFIX statistics to a collector consumes bandwidth. Offloading IPFIX generation to the NVF removes both problems.
Figure 1 displays what an NVF would look like in ACME’s data centre network. The green lines show where TAPs have been installed in the traffic path and are cabled to a central collector or packet broker. The orange lines show how traffic from the packet broker is sent to the appropriate tools.
Change is the Only Constant #
As business and application requirements evolve, the network will need to evolve as well. Security vulnerabilities will no doubt be exposed that need to be remediated to avoid exploitation. Network operating system lifecycles and bug fixes will force upgrades. Capacity may need to be added. Whatever the reason, there will be changes.
All significant changes should send the network through a spate of tests to ensure it still supports all business requirements. Periodic testing would make sure even minor changes are tested in batches. In a perfect world, every aspect of the data centre network would be duplicated in a lab environment so that all modifications could be tested there first. Even if ACME had the funds to do this, they couldn’t duplicate the types of traffic and the load and flow experienced in production. Invariably, there is some level of risk associated with every change, so ACME has provided only a subset of the network in a lab environment.
Documentation should not be immune to change. Be a team player and document, document, document.
The next post in this Back to Basics series discusses troubleshooting.