
This post on The Network Lifecycle is the sixth and final post in this Back to Basics series. Gathering Requirements, Network Design, Network Implementation, Network Operations and, Troubleshooting.
It is generally accepted that every network has a lifecycle and that a model can represent this lifecycle. Whether you use the six-step model shown in Figure 1, the three-step model depicted in Figure 2, or something completely different, all models share common elements.
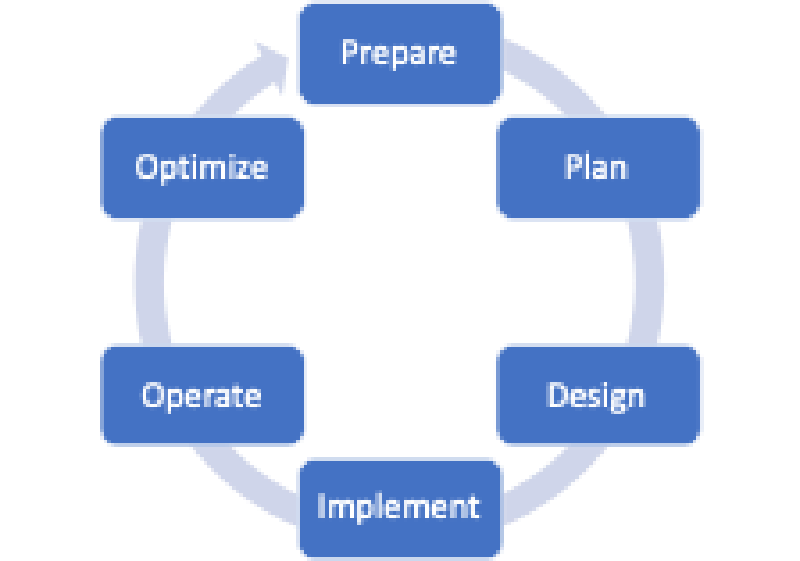
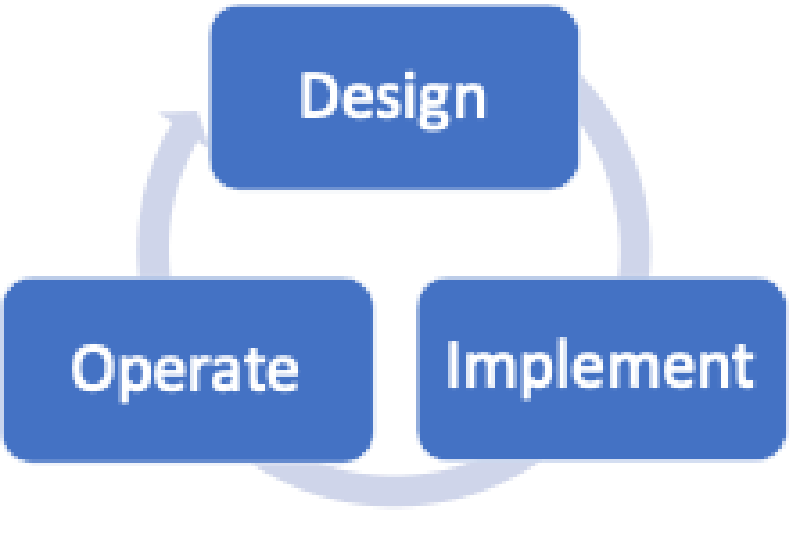
It is often challenging to decide on which box of a model to place the elements of a network lifecycle. One of the main reasons is that many elements appear multiple times. Another reason is that some elements may blur the lines of roles and responsibilities. Below is a list of common elements. In which box would you place them?
Information Gathering #
The most apparent form of information to gather is requirements. The first post in this series discussed gathering requirements to design the initial build. Truth be told, requirements gathering never stops. Business requirements tend to morph over time, and so do the applications that the business relies on. The network needs to keep pace with these changes.
Information about existing and newly built networks should also be gathered. Day-to-day information should include Central Processing Unit (CPU) utilization, bandwidth utilization, memory utilization, bit error rate, and packet drops, among others. Failure analysis reports are also critical for improving the system.
Information Analysis #
Day-to-day information is the easiest to deal with, as it is already in a technical form. This information should reveal whether network gear and links have been sized appropriately.
Failure analysis reports usually require a little more attention and effort than operational information. If the network has not responded as expected to a failure event, it must be determined whether the design needs improvement or whether mistakes were made during implementation.
Business and application requirements usually require the most elbow grease. This type of information must always be translated into technical requirements to be incorporated into a design. It would be great if every application clearly stated its network requirements in a meaningful technical format. However, such application documentation is rarer than rocking horse manure.
Architecture and Design #
The second post in this series, Network Design, discussed creating high-level and low-level design documents. The high-level document is called the architecture, while the low-level document is called the design. Depending on the organization and its division of labour, different resources might be responsible for producing each document, or the same resource might produce both. Not surprisingly, these resources are responsible for turning technical information into network architectures and designs.
New information gathered from the business or an existing network should always be reviewed by architecture and design resources to determine whether a change or optimization is required. Staying true to this process should help create and maintain consistency. A consistent network experience benefits the business, its applications, its users, and the resources tasked with its maintenance and operations.
Implement and Test #
The initial build of a network should pass through a few gates before being promoted to production. While configurations and some operations can be verified in a lab setting, bandwidth, error rates, and resiliency testing should be performed on the production equipment with synthetic traffic. Trying to support production workloads is not the optimal time to find a problem that could have been exposed with a rigorous proof of concept.
There are few changes made to production networks that do not require rigorous testing. Any modification that affects traffic flow (i.e., diverts, restricts, or increases it) should be tested. Any alterations to resiliency and failover settings need to be tested as well.
Your organization may have created a Business Continuity Plan (BCP) that includes Disaster Recovery (DR) to alternate sites. This plan should include periodic testing of all DR components to ensure they function as designed in the event of a disaster.
Operate #
A good operations team can make a lousy design tolerable to the business for some time. A negligent operations team can cause even the best-designed networks to drive like a rusted-out jalopy. Networks need care and feeding in the form of security patches, bug fixes, upgrades, effective troubleshooting and supervision.
Recurring issues should be documented and shared with the architecture and design resources. This process requires excellent communication and a healthy relationship between the two parties. It is tempting to implement simple design changes without consulting the architecture and design teams. No matter how innocuous a design change might seem, the final decision lies with architecture and design. This rule supports the continuity and consistency arguments made above.
A Networker’s Work is Never Done #
I have talked about iteration throughout this train of posts, so it is appropriate for it to be the caboose.
It should be evident by now that no part of networking is one-and-done or set-it-and-forget-it. The waterfall approach generally leads to suboptimal results when applied to networking. Iteration allows for repetition inside each stage of the network lifecycle. It also allows for both forward and backward motion between the stages. This freedom of motion enables fine-tuning at every stage and the incorporation of new information with greater ease, lessening the burden of rework.
Now go forth and network, cycling and iterating your way to success.